python nn 聲音辨識 -1 傅立葉轉換
辨識環境聲音判斷出這是甚麼聲音
主要想法是用頻域赫茲分布做判斷首先先錄三種聲音的聲音檔,我每一種聲音重複錄製九個sample,所以有27個wav檔
讀取wav檔案,作正規劃處理,在做傅立葉轉換
一開始由於自己做的fft_domyself() function跟其他聲音處理軟體做出來的不一樣,數值非常小,之後找到有內建的spectrogram() function,使用也是數值很小,最後才想到要20log(),但由於內建的覺得不適合自由調整,所以還是修改自己的function。
import matplotlib.pyplot as plt
from scipy.fftpack import fft
from scipy.io import wavfile # get the api
import numpy as np
from scipy import signal
import math
import pyaudio
import wave
import time
#buf=[]
#讀入單一檔案測試
def init():
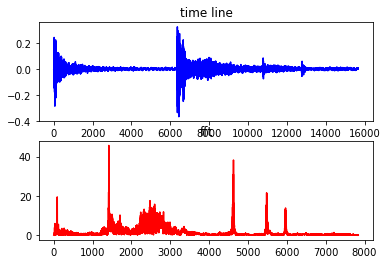
fs, data = wavfile.read('0106.wav') # load the data
b=[(ele/2**16.) for ele in data] # this is 16-bit track, b is now normalized on [-1,1)
c = fft(b) # calculate fourier transform (complex numbers list)
d = len(c)/2 # you only need half of the fft list (real signal symmetry)
plt.subplot(211)
plt.plot(b,'b')
plt.title('time line')
plt.subplot(212)
plt.plot(abs(c[:(d-1)]),'r')
plt.title('fft')
plt.show()
return fs, b #取樣率 data
#轉成頻域
def fft_domyself(b, fs, plotshow=None):
global ftmap
#set value
one_second_block_num = 21*2 #one second 擷取次數
second = len(b)/44100
second_len = int(one_second_block_num*second)
fft_num = int(fs/one_second_block_num) #one second 間格點數 #2100
ftmap = np.zeros((int(fft_num/2),second_len)) #建立fft陣列的圖片大小
startime = 0#362000
#轉成fft 並儲存在fft陣列
for i in range(0,second_len):
endtime = startime + fft_num
ffttemp = abs(fft(b[startime:endtime]))
ftmap[0:fft_num,i] = ffttemp[0:int(len(ffttemp)/2)]
startime = endtime
#做20log()
for i in range(0, len(ftmap[:,1])):
for j in range(0, len(ftmap[1,:])):
try:
#ftmap[i,j] = 20*math.log10(ftmap[i,j])
ftmap[i,j] = 20*math.log(ftmap[i,j], 10)
except:
#由於 log(0) 輸入0會error
print('log error with ftmap: ', ftmap[i,j])
ftmap = ftmap + abs(np.min(ftmap))
lineft = np.median(ftmap, axis=1) #用二維的方式,查看頻域的整體資料情況
if plotshow:
if plotshow == 'linefft':
plt.plot(lineft, 'b')
plt.show()
else:
plt.plot(lineft,'g')
plt.show()
plt.imshow(ftmap)
plt.xlabel('Frequency [Hz]')
plt.ylabel('Time [sec]')
plt.colorbar()
plt.show()
return ftmap, lineft
#使用內建的function將聲音轉成頻域
def spectrogram_(b, fs, plotshow=None):
#x1 = np.array(b, dtype = float)
f, t, Sxx = signal.spectrogram(b, fs) #output 時頻譜
for i in range(0, len(Sxx[:,1])):
for j in range(0, len(Sxx[1,:])):
Sxx[i,j] = 20*math.log10(Sxx[i,j])
#print('do')
Sxx = Sxx + abs(np.min(Sxx))
if plotshow:
plt.pcolormesh(t, f, Sxx) #draw 時頻譜
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
plt.colorbar()
plt.show()
return Sxx
if __name__ == '__main__':
fs, b = init()
fftmap = fft_domyself(b, fs, plotshow = True) #自己做的
sx = spectrogram_(b, fs, plotshow = True) #內建function
2018/2/24更新(添加註解)
img
lineft

ftmap

spectrogram_()

讀多個聲音檔,並轉換成fft矩陣
我是用三個鈴鐺做的,無聲音檔就是沒有鈴鐺聲只有背景聲

輸出:
linef = [0~20000Hz頻域的大小 , 0~20000Hz頻域的大小 , 0~20000Hz頻域的大小 ......]
answer = [ [0.0 , 1.0 , 0.0 , 0.0] , [0.0 , 0.0 , 1.0 , 0.0] , [0.0 , 0.0 , 0.0 , 1.0] ......]
[0.0 , 1.0 , 0.0 , 0.0] 代表是第一類聲音
def read_file(filename, plotshow=None):
fs, data = wavfile.read(filename) # load the data
b=[(ele/2**16.) for ele in data] # this is 16-bit track
if plotshow:
plt.plot(b,'b')
plt.title('time line')
plt.show()
return b, fs
def read_to_mat():
file_road = './train_data/'
filehead = ['00', '01', '02', '03']
linef = []
answer = []
for i in range(1, 10): #last two number
for j in range(0, len(filehead)): #first two number
readURL = file_road + filehead[j] + '%02d'%(i) + '.wav'
x = [0.0, 0.0, 0.0, 0.0]
x[int(filehead[j])] = 1.0
audio_value, fs = read_file(readURL)
fftmap, linefft = fft_domyself(audio_value, fs)
normalized_linefft = (linefft - np.mean(linefft)) / np.std(linefft)
answer.append(x)
linef.append(normalized_linefft.tolist())
print(readURL, x)
return linef, answer
錄製聲音def recoder(recoder_second, filename = None, plotshow=None):
NUM_SAMPLES = 100 # pyAudio內部緩存的塊的大小
SAMPLING_RATE = 44100 #取樣頻率
#recoder_second = 1
'''
LEVEL = 1500 #聲音保存的閾值
COUNT_NUM = 20 # NUM_SAMPLES個取樣之內出現COUNT_NUM個大於LEVEL的取樣則記錄聲音
SAVE_LENGTH = 8 #聲音記錄的最小長度:SAVE_LENGTH * NUM_SAMPLES個取樣
skip_second = 0.07
swidth = 2
'''
#開啟聲音輸入
save_buffer = []
pa = pyaudio.PyAudio ()
stream = pa . open ( format = pyaudio.paInt16 , channels = 1 , rate = SAMPLING_RATE , input = True , #output = True,
frames_per_buffer = NUM_SAMPLES ) #,stream_callback = callback
time.sleep(0.1)
stream.start_stream()
skip_buffer = []
num = 3500 / NUM_SAMPLES#SAMPLING_RATE / NUM_SAMPLES * skip_second
for i in range(0, int(num)):
string_audio_data = stream.read ( NUM_SAMPLES)
skip_buffer.append(np.fromstring(string_audio_data, np.int16))
#stream.read ( NUM_SAMPLES)
print('star recoder')
num = SAMPLING_RATE / NUM_SAMPLES * recoder_second
for i in range(0, int(num)):
#讀入NUM_SAMPLES個取樣
string_audio_data = stream.read ( NUM_SAMPLES )
save_buffer.append(np.fromstring(string_audio_data, np.int16))
#stream.write(string_audio_data, NUM_SAMPLES)
print("* done recording")
stream.stop_stream()
stream.close()
pa.terminate()
numpydata = np.hstack(save_buffer)
skipnp = np.hstack(skip_buffer).tolist()
'''
#直接存檔
WAVE_OUTPUT_FILENAME = filename + ".wav"
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(1)
wf.setsampwidth(pa.get_sample_size(pyaudio.paInt16))
wf.setframerate(SAMPLING_RATE)
wf.writeframes(b''.join(save_buffer))
wf.close()
'''
if plotshow:
if plotshow == 'line':
plt.plot(numpydata,'r')
plt.show()
else:
plt.subplot(311)
plt.plot(skipnp,'g')
plt.subplot(312)
plt.plot(save_buffer,'b')
plt.subplot(313)
plt.plot(numpydata,'r')
plt.show()
return numpydata, SAMPLING_RATE
if __name__ == '__main__':
buffer = []
recoder_second = 0.5
buffer, fs = recoder(recoder_second, plotshow=True)
fttmap, linef = fft_domyself(buffer, fs, plotshow = True)
開始錄音時發現會有一個雜訊,那個雜訊值非常大,以下是跳過雜訊再錄音0.05秒,green line是跳過的雜訊,blue line是接續綠色後面的0.05秒錄音

blue line:原始錄到的資料,每一點的資料量跟 (NUM_SAMPLES = 100 # pyAudio內部緩存的塊的大小) 有關
red line:將blue line的資料串接起來



請問如何辨識出來~然後自動分類....
回覆刪除我到第25行的地方就不太行了
求高手教QAQ
自動分類?! 類神經網路就直接讓他學習就好 他會自己處理
刪除但是你給他訓練的資料(聲音檔)要自己分類喔
抱歉!!~我不知道你指的第25行是指哪一段的25行
作者已經移除這則留言。
刪除我是不知道轉速的聲音有沒有差別 但最好能擷取較無雜訊的音訊
刪除其實我真正用程式錄音方式下去做其實誤差非常大 我是用鈴鐺聲音 用程式錄音就沒辦法把前後雜音的部份去掉 我先前的錄音檔是有經過去除無鈴鐺聲音的部分 所以成功機率較高
所以基本上要將聲音去頭去尾 只留下真正需要的部分
我這個其實是很陽春版的 只是用來實驗 聲音也能分類
其實他主要還是用圖像的方式做神經網路 你可以以圖像的角度去看待它會比較清楚 網上有很多對於圖像的範例
有沒有不經過圖像,直接用FFT轉換後數字化,用全數字的檔案辨識的方法
回覆刪除你所說的全數字的檔案跟我說的圖像意思其實是一樣的,一張黑白照片其實就是一個全數字檔
刪除FFT轉換後一定會轉成我第四張圖那樣,一個二維的圖每一個像素點就是一個數字啊!!
版主你好~想請問第一段第二張做出來紅色的圖的Y軸的數值代表什麼意思?為什麼需要透過abs讓他全部都為正的?還有第三張綠色的圖的X軸和Y軸又分別代表什麼意思呢?謝謝
回覆刪除有點久了幾乎忘記當初在做甚麼,回答可能不一定正確先跟你說聲抱歉了。
刪除我想紅色的Y軸應該是傅立葉轉換出來的大小,abs轉正是為了視覺上的習慣,像是音樂撥放器或是收音設備上的頻譜都沒有顯示負值,所以就習慣看沒有負值。
綠色的圖 (lineft) 應該跟 ftmap 是一樣的意思,在ftmap上有軸的說明,所以綠色的圖 (lineft) X軸應該是Hz吧!? Y軸應該就是值的大小了。
最近研究雜音捕捉看到這篇,16-bit wav 有一位是符號,b=ele/2^16結果應該是-0.5~0.5才對,才會有數值非常小的問題。
刪除20log()是音壓,據我理解,如果是處理錄製結果,資料數值應該是變回音強。